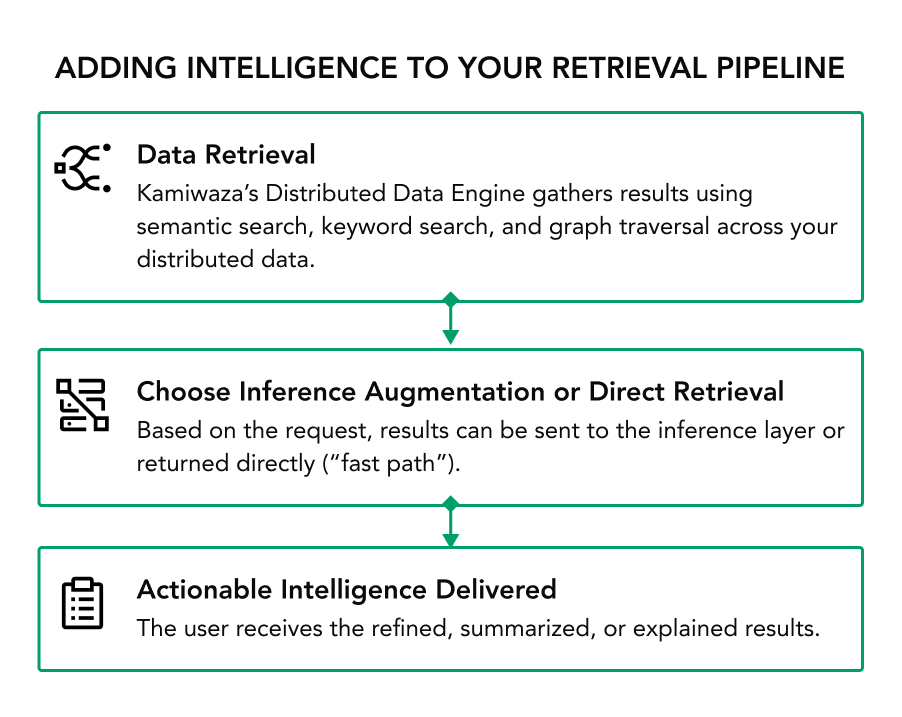
Even when your retrieval systems can find the right data, users often struggle with too much information and not enough understanding.
- Information overload - Users get long documents or complex datasets, but don’t have time to synthesize them into actionable insights.
- Lack of context - Raw results often need explanation or connection to broader context, which standard search can’t provide.
- The security risk of cloud LLMs - Sending internal search results or sensitive data snippets to a public cloud LLM API is a major security and compliance violation waiting to happen.
- Limited model choice - You might be locked into a single provider’s LLM, unable to use the best model for a specific task.
With the power of LLMs applied to your internal data, you can make faster decisions that are backed by real business intelligence.