
Do you remember that time your enterprise architect tried to capture all of the company’s terminology and the relationships between those terms, “once and for all”? You know, to increase understanding and to make sure future projects didn’t muddy the waters further by introducing confusing concepts into company operations?
How did that work out?
One of two things probably happened. Perhaps you did in fact get a really cool artifact that brought clarity to both the business and software development. For some period of time, everyone understood what everyone else was talking about. But then, just a year or two later, things had drifted far enough from the model that fewer and fewer people used it.
Perhaps solutions that didn’t fit the model were delayed as enterprise architecture tried to figure out how to fit a new concept into their nice neat model. And, in either case, the organization just didn’t have the energy to go through the process of maintaining or even rethinking the entire model.
Or maybe neither of those things happened. Maybe you never even got to a clean model of your organization’s ontology. After spending months and months trying to get everyone to agree on terms, relationships, and mechanisms to govern how those things might change, the entire project was simply abandoned.
Does that mean that ontologies aren’t useful? That an accurate (or at least plausible) artifact that aligns everyone around semantic and organizational meaning is not worth the effort?
The Value of Ontologies
Of course not. Ontologies are a powerful mechanism for humans to avoid misunderstanding and conflict as they attempt to coordinate complex sets of work, processes, and data representation. Companies that maintain informal ontological consistency (through training, documentation, and formal architectures) often move faster with less error than organizations that are constantly resolving differences in understanding enterprise state.
But in the age of AI, ontologies are even more essential. The success of every agent, or even every prompt, is dependent on understanding context. And in enterprise AI, that context is represented by data stored in databases, documents, or even event or message streams. And it’s not just the data itself that models might consider context, but the relationships within the data.
While building stand-alone agentic solutions might allow developers to work out relationships on behalf of AI, building self-organizing systems at scale can’t afford to wait for understanding from humans. Understanding should be embedded in the context in which the AI solutions are working.
Living Ontologies Maintain Understanding
As is often the case, where AI exposes a problem, AI can be a big part of the solution. Kamiwaza is predicated on the concept of a living ontology: a constantly maintained and evolving representation of the meaning of data. In Kamiwaza, that representation takes three forms:
- Metadata about data location, their types, and the form of data storage. (For the purposes of this discussion, message and event queues are a form of storage.)
- A semantic vector map of the data terminology, to allow easy understanding of similar terms. For example, “‘customer” means the same thing as “buyer” in this context.)
- A graph representation of the relationships between data elements, such as “projects belong to organizations” or “order 1234 contains a subscription to service X.”
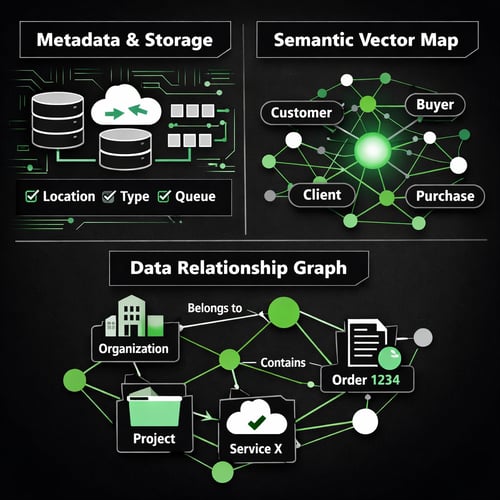
As you can see, this is very analogous to other forms of indexing in databases, but has a level of intelligence and interpretation that requires more than a simple sort algorithm.
When Kamiwaza is asked to build an ontology, it first extracts the relevant information from the data sources, and then uses AI models with minimal human guidance to build and maintain the three indexes I listed above. We make sure we understand where the data came from, what it means in terms of language, and how it fits into the known relationships with other data elements. All shepherded by an outline of concepts important to the business.
Just as ontologies quickly became out of date in the past, all three indexes constantly change. But unlike the past, all three are kept consistent with each other, and all three evolve as more data is collected, more data sources are ingested, and more relationships are established. AI works out the mechanisms and rules as it gets feedback from the humans in the loop.
What Living Ontologies Enable
When you give AI context that includes data, semantic meaning, and ontological relationships, it’s almost like a magic trick. (It isn’t a magic trick, of course, as real resources are required to maintain an accurate ontology.)
- Suddenly, AI actions that augment inference with enterprise data become fast—and in the case of Kamiwaza, inherently distributed—spanning infrastructure in the same way data itself is accessed, maintained, and interpreted.
- The software and hardware systems required to support enterprise-scale inference no longer need to be centrally managed, but can instead be owned and operated by different teams across IT and the business.
- The process of creating and maintaining ontology can be decoupled from the processing of inference to consume the data itself. This has real implications for the distribution of hardware resources. GPU-heavy server farms might be used for building and maintaining ontology centrally, while inference will require much less processing and can, in simple cases, be run on systems that are entirely CPU-bound. Which is great for edge computing, maintaining smaller (and cheaper) models for specific data access use cases, and mitigating heat, water, and power requirements.
- Multiple techniques can be used to inject data into inference. Data can be retrieved through Kamiwaza’s Dynamic Data Engine, for instance, while the prompt is being created (before inference even begins), or as an advanced form of RAG during inference.
- Different models can be used for different purposes, as well. Large parameter models can be used for ontology services and for very complex research and calculation tasks, while smaller open source and commercial models can be used for basic data augmentation and inference tasks.
The key is that the processing necessary to understand contextual relationships and build the shared enterprise data “memory” is decoupled from basic inference to use that “memory” in basic analysis and decision making. And that decoupling has an impact on financials, human organizations, and performance.
Why Kamiwaza Ontologies Are Game Changers
All of this is why Kamiwaza is so fundamentally different from other AI orchestration approaches. We aren’t building a “platform” for defining agents while expecting the models (or even MCP tools) to solve data access. We are making data a first class citizen of AI inference. We are also using ontology to secure access to data, maintain location or classification sovereignty when required, and to allow agent developers to abstract data access entirely from agent or model configuration.
This is why Kamiwaza changes the game for enterprises. This is why enterprises realizing the breadth and depth of AI integration with their existing data systems are choosing Kamiwaza to empower rapid systems development.
Learn more about Kamiwaza's approach to living ontologies.
As always, I write to learn, so please feel free to comment below with your thoughts or questions.