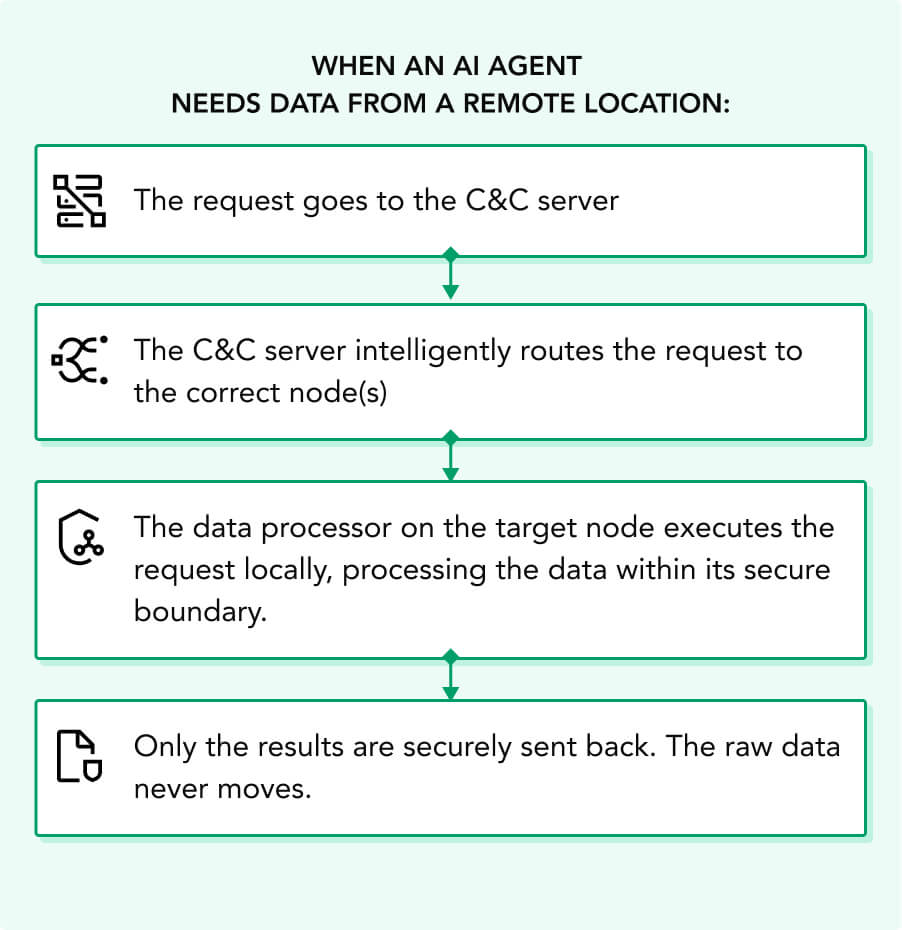
Traditional AI demands the impossible: centralize all your data first. This approach fails because your enterprise reality is distributed.
-
Data is too big - Moving petabytes of data across networks is incredibly slow and expensive. Your real time AI needs cause you to get held up on historical analyses.
- Data is too sensitive - Security policies and regulations like GDPR or HIPAA strictly prohibit moving sensitive customer, patient, or financial data outside secure boundaries.
- Infrastructure is too complex - Your data lives across multiple clouds, on premise legacy systems, and edge locations. Building and maintaining pipelines to centralize this is an operational nightmare.
- Innovation is blocked - If you can’t move data to where traditional AI tools run, you simply can’t use most AI services.