
A jointly developed and validated solution through the HPE Unleash AI program
HPE, NVIDIA, and Kamiwaza are jointly introducing a validated inference architecture through the HPE Unleash AI program that delivers up to 20x faster time to first token and up to 17x higher effective inference throughput. Time-to-First-Token (TTFT) determines the perceived responsiveness of an AI, as it measures how quickly the user sees the start of a response, while inference throughput determines the system's efficiency and cost-effectiveness by measuring how many total tokens or requests can be processed simultaneously. The solution replaces local KV cache with persistent, shared cache over Remote Direct Memory Access (RDMA), combining HPE Alletra Storage, HPE ProLiant Compute, and Kamiwaza's AI orchestration platform into a jointly integrated and production-ready deployment. Validation was conducted on NVIDIA H200 and NVIDIA RTX PRO™ 6000 Blackwell GPUs, with ongoing testing across NVIDIA Llama Nemotron™ 70B models.
The architectural challenge of large-context, high-concurrency inference
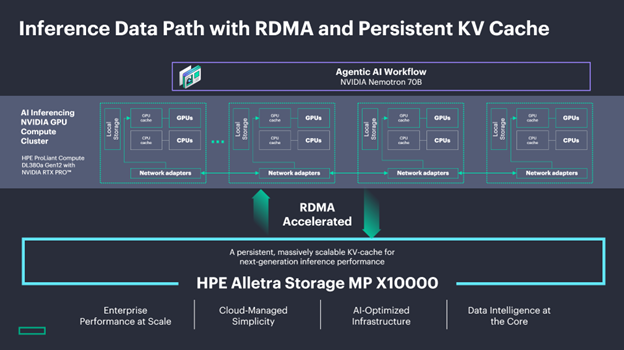
As enterprise AI workloads scale in context length and concurrency, the efficiency of the inference data path becomes increasingly determinative of overall system performance. KV cache, the stored key-value pairs that allow a model to reference prior context without repetitive inference, is central to that efficiency. In traditional deployments, KV cache is local to each inference server: siloed per host, lost on reboot, and inaccessible to other nodes. Under sustained concurrent load, cache hit rates can approach zero as incoming requests overwrite one another, forcing full prefill re-computation across every query. In large-context scenarios with many concurrent users, that re-computation compounds rapidly across the cluster, consuming GPU cycles that would otherwise be applied to new inference work.
Persistent, shared KV cache over RDMA
Remote Direct Memory Access provides data path architecture that makes centralized, persistent KV cache practical at inference speeds. By using zero-copy memory transfers and direct NIC-to-memory communication that bypasses the kernel TCP/IP stack, RDMA eliminates CPU mediation from GPU-to-storage data movement, reducing latency to the point where offloading cache to shared storage becomes operationally viable.
In this architecture, HPE Alletra Storage MP X10000 serves as the centralized cache layer, delivering the throughput and latency characteristics required to serve KV cache at scale. Multiple vLLM servers draw from the same cache pool, so prefixes persist through server restarts, cached context generated by one node is immediately available to others, and redundant prefill computation is eliminated across the entire cluster rather than just within a single server.
Enhance performance results: What the numbers show
Validation testing on HPE ProLiant Compute DL380a Gen12 with 8x NVIDIA H200 NVL configuration running NVIDIA Llama Nemotron™ 70B models with 96 concurrent requests and 50,000-token context windows produced the following results:
| Configuration | Avg TTFT | TTFT Speedup | Ave Query Time | QT Speedup |
| Baseline (vLLM, no KV cache offload) | 288.2s | — | 573.3s | — |
| LMCache + HPE Alletra GDS — Average | 15.5s |
18.6x |
37.3s | 15.4x |
| LMCache + HPE Alletra GDS — Peak | 14.1s | 20.4x | 33.8s | 16.9x |
|
Peak single-run performance: up to 20x faster time to first token and up to 17x faster query time vs. baseline. Results represent average of 3 runs for average figures. Performance varies by workload, configuration, model, and system environment. February 2026. |
||||
To put the throughput figure in operational terms: the same cluster that handled a given concurrent workload at baseline sustained up to 17 times that workload with RDMA-enabled persistent cache, within the same hardware footprint. For organizations projecting infrastructure requirements against growing AI demand, that changes the capital planning calculus significantly.
Where this delivers the most impact
Life sciences. Pharmaceutical and biotech teams repeatedly analyzing shared document corpora such as clinical trial protocols, safety reports, and prior submissions across multiple reviewers and iterative query sessions see high rates of prefix reuse. Less re-computation means faster analysis during submission cycles and higher throughput within the same infrastructure footprint.
Financial services. Portfolio analysis, regulatory filing review, and macroeconomic modeling involve concurrent agents accessing overlapping datasets across teams and trading scenarios. Shared persistent cache means those datasets are not reprocessed each time a different agent queries related context, improving both response time and overall cluster utilization.
Energy and industrial. Field engineers and operations teams querying decades of maintenance logs, schematics, and safety procedures represent a natural fit for this architecture. When many engineers draw from the same technical corpus, centralized cache means the computational work of the first query benefits all subsequent ones.
Media and entertainment. Studios managing large content libraries for localization, repurposing, and AI-assisted creative workflows benefit from persistent cross-team cache when distributed teams work from the same archive simultaneously.
A jointly validated, production-ready solution
This architecture is available through the HPE Unleash AI program, bringing together HPE Alletra Storage MP X10000, HPE ProLiant compute with NVIDIA RTX PRO™ 6000 BLACKWELL Server Edition, and Kamiwaza's AI orchestration platform as a jointly integrated and validated deployment. Performance characteristics are proven under realistic enterprise workloads rather than isolated benchmarks, and the solution is designed for production deployment on NVIDIA RTX PRO™ 6000 BLACKWELL Server Edition. Validation on the new NVIDIA Nemotron 3 Super is ongoing.
For infrastructure leaders evaluating how to maximize the output of existing GPU investments before the next expansion cycle, RDMA-enabled persistent KV cache is a validated architectural improvement with measurable, documented results. The workloads that benefit most are exactly the ones enterprises are scaling fastest: large-context document analysis, high-concurrency agent deployments, and repeated interaction with shared knowledge corpora across distributed teams.
Test Configuration
| Component | Details |
| Server | HPE ProLiant Compute DL380a Gen12 |
| GPU | 8x NVIDIA H200 NVL |
| Storage | HPE Alletra MP X10000 |
| OS | Ubuntu 24.04.3 LTS |
| Nvidia Driver | NVIDIA-SMI 590.48.01 CUDA Version: 13.1 |
| LLM | NVIDIA Nemotron 70B |
| Inference Framework | vLLM [version TBD] + LMCache [version TBD] |
| KV Cache Backend | Kamiwaza custom LMCache backend (HPE Object SDK) |
| Max Model Length | 61,000 tokens |
| Concurrent Requests | 96 |
| Request Context Size | 50,000 tokens |
| Test Date | February, 2026 |


