
I’ve had the privilege of talking to a lot of people about enterprise AI, the use of data in creating action and insight, and the challenge of scaling practices and technology across a large number of teams. Without exception, the technology professionals I talk to are finding insanely cool things to do with AI, but have not yet figured out how to scale those successes to their entire company without creating new security, governance, and performance challenges.
At Kamiwaza, we’ve thought a lot about what is necessary to address “enterprise scale.” In many ways, the challenges that AI-based software brings to the enterprise are similar to those of any distributed systems environment, such as social media sites or big data analytics platforms. But there are some key differences, namely the software is now a collaborator with your human resources, and must be treated as such.
So, with an eye towards explaining how enterprise scale is achieved in AI systems, let me explain Kamiwaza’s perspective and how our platform addresses this challenge.
Much More Than RAG
Kamiwaza is an orchestration platform that sits between your AI applications and agents and your distributed enterprise tools and data. (Tools can be anything accessible via MCP or a script, such as databases, SaaS applications, and so on. A good example is the Linear MCP server we use to integrate with our issue tracking system.)
As such, Kamiwaza has one key responsibility: to make those tools and data usable in creating intelligent, accurate results. This requires a combination of models, data sources, tool access, and application (or agent) awareness.
I look at these needs in three categories: context, security, and collaboration.
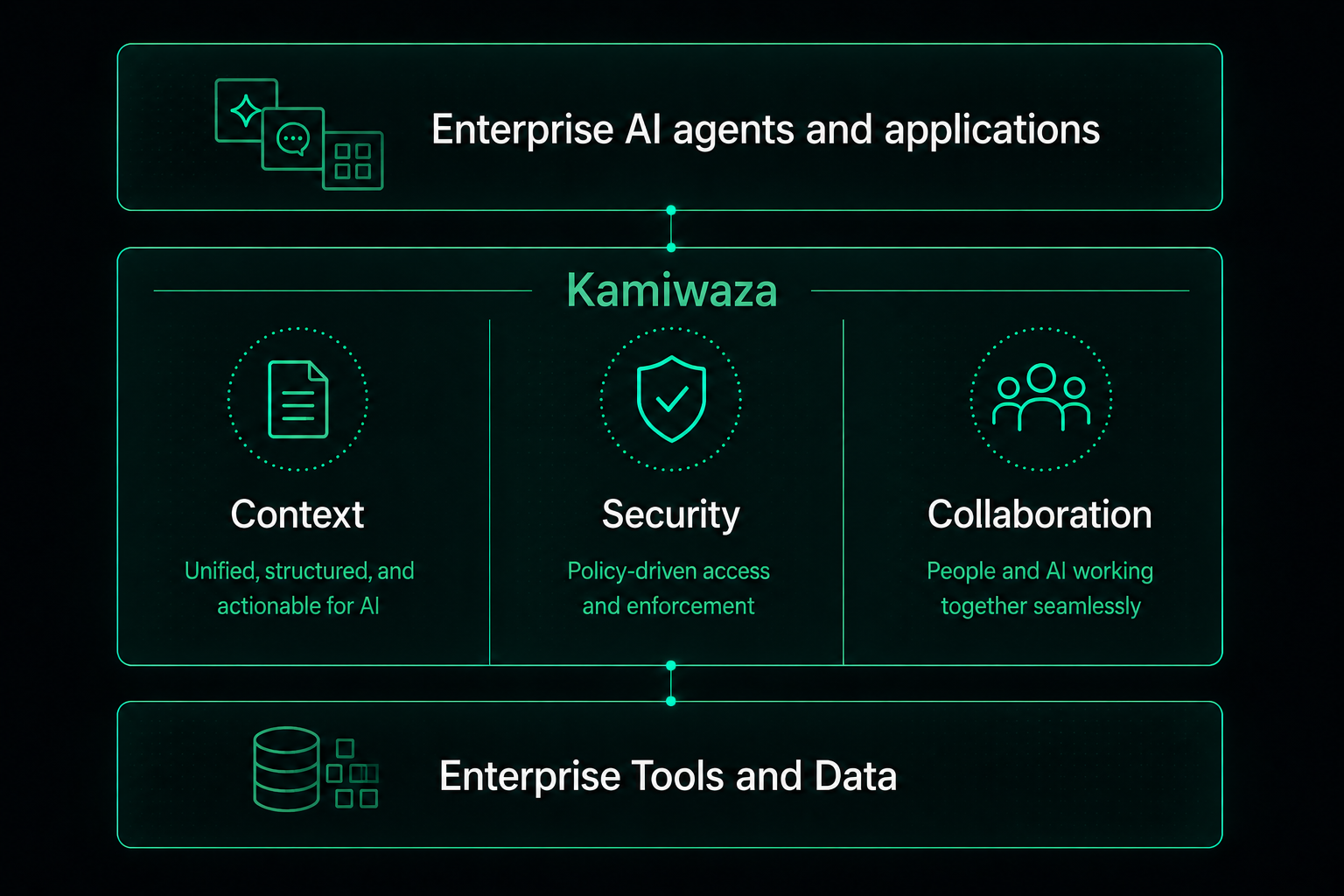
Context
One can consider the corpus of enterprise data as the baseline context for understanding the current state of the business. In the modern era, generally whatever matters is stored in a database or digital document somewhere, and the platform’s responsibility is to understand the data, and make the right data available to AI models when it is needed.
Security
However, once you consider the entire company’s available data as context, you quickly realize two things. First, not all people in the organization (or outside of it, for that matter) should have access to all of the data. There needs to be guardrails to assure that humans, agents, and applications can only access the data they are authorized to access when fulfilling a prompt. Second, there must also be assurances that the data environment is not vulnerable to security vulnerabilities like back doors, zero day attacks, and so on.
Collaboration
Finally, even with proper access controls in place, individual people or teams may want to narrow that context down even further for specific needs. For example, a research team may want to have ongoing AI conversations about design and test data without sharing the details of their project with other teams. The ability for that team to work in an independent context while sharing the guardrails and data access capabilities of the platform is a game changer for discovering AI-led productivity gains.
This simple model is the difference between scrambling to handle demand for AI data access and having the problem already solved for new applications and agents as they are developed. Let’s explore each in more depth.
Building Context
 In modern LLM-driven AI, everything begins with context. Context is the information that AI loads into its algorithms to be used when generating a response. This can include information retrieved from data stores, MCP tools, and the like, or it can include information from previous work with the AI through “memory” of various sorts (e.g. remembering previous parts of the current series of prompts, remembering previous conversations, and so on.)
In modern LLM-driven AI, everything begins with context. Context is the information that AI loads into its algorithms to be used when generating a response. This can include information retrieved from data stores, MCP tools, and the like, or it can include information from previous work with the AI through “memory” of various sorts (e.g. remembering previous parts of the current series of prompts, remembering previous conversations, and so on.)
And the importance of context is now fairly well understood. Context is the way that AI understands current reality, rather than the reality that existed when it was trained. It is the way you give the model knowledge of your policies, your products, and even transactions in progress. It is highly doubtful that you build an AI system that impacts the bottom line of your current business model without creating context.
But there are two interesting problems that can appear when building context in response to a prompt. The first happens when you gather too little information; the model will often begin to “guess” at the right information. Which is a form of hallucination.
The second happens when you gather too much information. Now the model struggles to determine which information is most relevant to its response, which at best leads to much poor performance and at worse leads to the wrong context being used to build the response.
It seems like a scene straight out of “The Three Bears.” What enterprises are looking for is the “just right” amount of context for any given prompt.
Kamiwaza has demonstrated that the key to this optimization is the use of ontology, semantics, and smart data processing approaches to enable models to retrieve exactly what they need to build an accurate response to a prompt. Or as close to that as possible. We have even added checks during the retrieval process to confirm that we have the right information to build a response before the response is even built.
I like to think of it this way: when an agent wants to process a prompt, it shouldn’t have to navigate the complexity of data sources, tools, and so on on its own. An AI orchestration platform should just provide the right context and the right results automatically and consistently. That’s what Kamiwaza provides.
Keeping Context Secure
 Now, just because you can optimize context retrieval doesn’t mean that everyone should see all context whenever they want. Every enterprise has strict rules about who can see what data in what format, and for good reason. That data is valuable, and can often be used in aggregate to determine things that the organization would prefer to restrict in some way, such as when stock traders used private plane flight information to determine possible mergers before they were announced. Restrictions are often due to regulatory requirements (e.g. protecting quarterly financials before they are released), but there are a myriad of other reasons organizations restrict data access.
Now, just because you can optimize context retrieval doesn’t mean that everyone should see all context whenever they want. Every enterprise has strict rules about who can see what data in what format, and for good reason. That data is valuable, and can often be used in aggregate to determine things that the organization would prefer to restrict in some way, such as when stock traders used private plane flight information to determine possible mergers before they were announced. Restrictions are often due to regulatory requirements (e.g. protecting quarterly financials before they are released), but there are a myriad of other reasons organizations restrict data access.
For AI applications, what makes managing data access especially tricky is that you are not determining access for a single entity most of the time. Agentic applications, for example, have to understand the access rights of any agent working on behalf of multiple employees, all of which might have their own disparate access rights. Even more challenging is controlling access rights for an agent working on behalf of other agents or applications. Agents may have broad access rights to enable them to serve a wide variety of individuals (or other systems) with a wide variety of access rights of their own.
The combinatorics can get a bit crazy compared to the role or attribute based approaches we are used to. But there is a form of representing these relationships that can enable fine grained access control definition for humans and software alike: relationship-based access control (or ReBAC).
I’ve described ReBAC in depth in previous blogs, so I won’t repeat everything here. However, it is critical that an AI orchestration platform like Kamiwaza gets access right, and the use of policies defined on sets of relationships enables incredible flexibility and control. You can use it to define policies like “Agent A should have access to Data B on behalf of Employee C, but only if Employee C is still a part of Project X.” If the employee is no longer part of Project X, the agent immediately stops accessing the data on the employee’s behalf.
And these policies need to be checked not only for data access, but also to validate that certain actions are allowed. For example, MCP tool access may be restricted depending on some of the same conditions as data access. Kamiwaza checks access rights with every API call, and often before it takes certain actions during inference or tool usage. The enterprise can always be assured that, regardless of the prompts it receives, Kamiwaza will maintain the appropriate controls.
The Enterprise Formula: Security, Context, Collaboration
All of this goes back to my earlier argument that the AI market will divide around the interface between intelligence consumption and intelligence delivery. What an enterprise with a complex data portfolio, a broad organizational structure, and thousands of use cases really needs is the assurance that any prompt will get answered while adhering to key access policies, without requiring custom development for each use case.
Enabling wide-ranging experimentation with AI while allowing proven solutions to scale and mature is the core secret. By following this approach, you build AI support in your organization while empowering existing skills to contribute in their best capacities. Furthermore, new technologies, such as agent orchestrators, can be added to your portfolio without jeopardizing the security of your data and context.
Kamiwaza is built to enable enterprises to build the right context securely every time, without requiring major changes to the existing data infrastructure. To find out more about why some of the most security sensitive organizations in the world trust Kamiwaza, check us out at https://kamiwaza.ai.
As always, I write to learn, so if you have questions or comments, please share them in the comments below, or find me on LinkedIn at https://www.linkedin.com/in/jurquhart. I look forward to hearing from you.


